Monitor folders - split new PDF files automatically
Step-by-step instructions for automatically splitting PDF files with Automatic PDF Processor for Windows
Video tutorial: Automatically split PDF files (with narration and optional subtitles)
Introduction
In this tutorial, we will show you how to set up a hot folder to auto-split PDF files. After the profile has been created, all
new PDF files in this folder will be automatically split into multiple, separate documents according to the rules you defined
here. You can also batch split already existing PDF documents using the Catch-up function from the upper toolbar.
Create a new profile
Click the "New profile..." button in the toolbar to create a new profile. Enter a meaningful profile name in the
configuration window - for example, "Split collective invoices" or "Split collective protocols". Optionally,
add a comment, for example, the destination folder. You can have the profile color-coded to quickly distinguish performed tasks
in the log list.
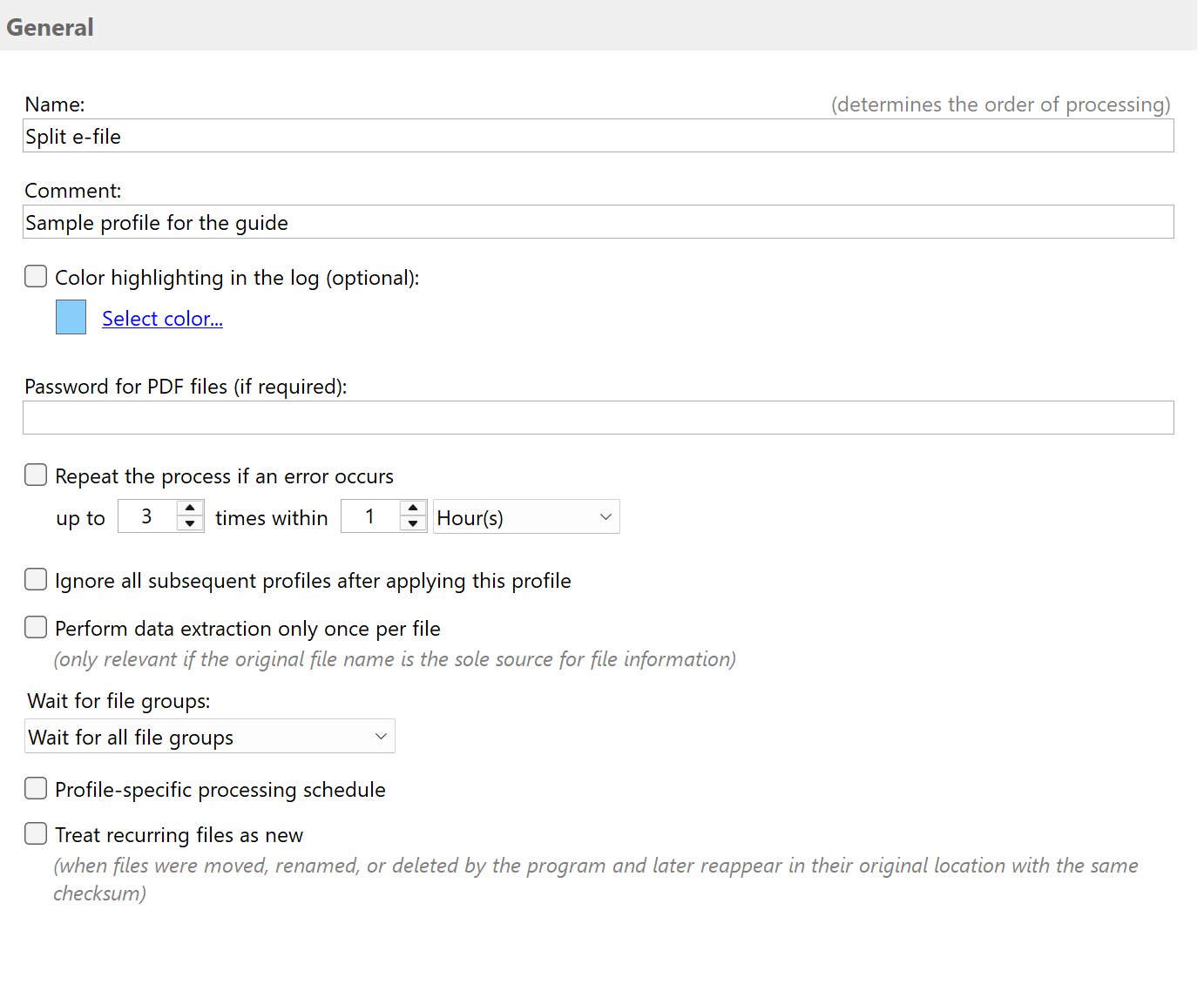
Specify the folder to be monitored
Next, specify one (optionally several) folders to be monitored. As soon as new PDF files arrive in the folder, the program will
detect and process them automatically - in this case, splitting them. Click the Add button and select one of the folders listed
there.
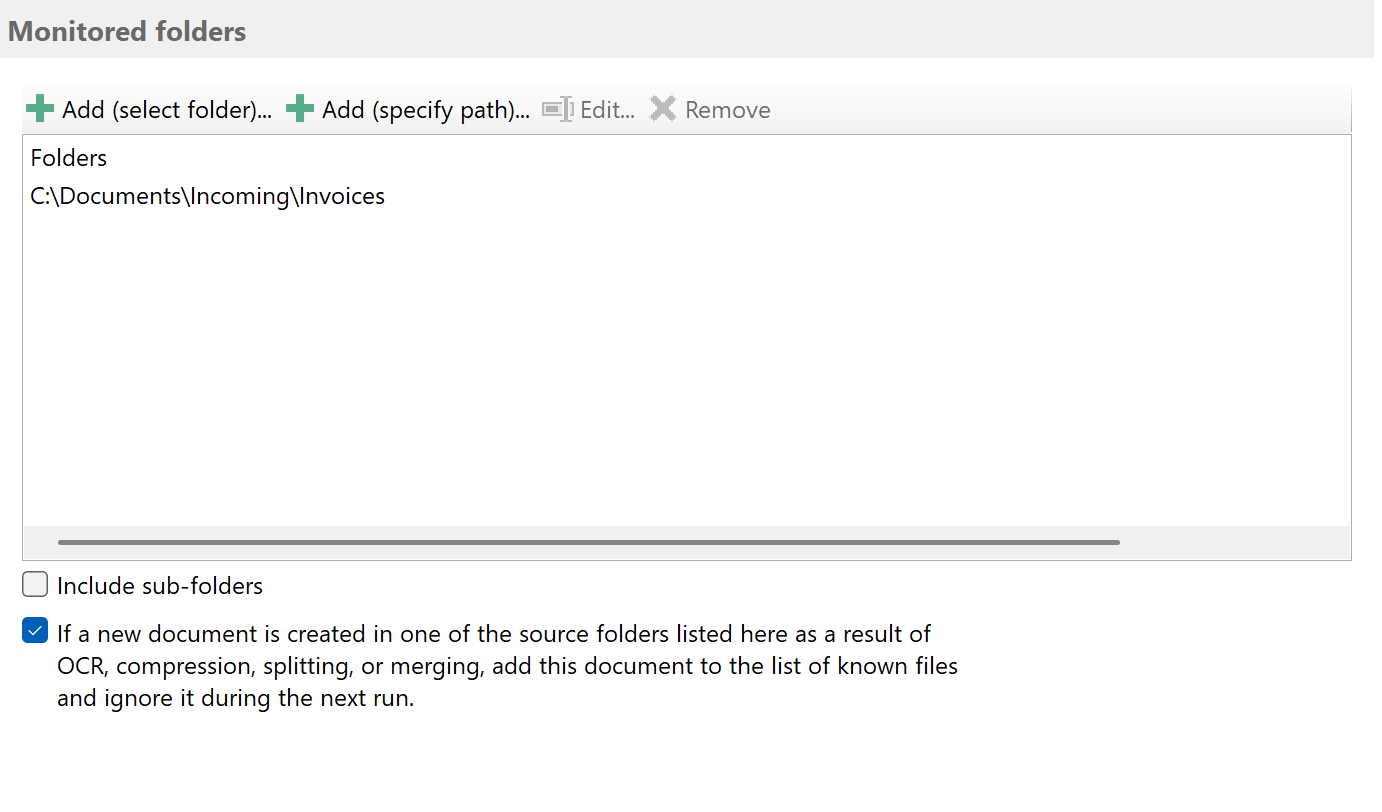
Set up one or more filters
Optionally, set different filter criteria here to separate only specific PDF files. You can use file properties like part of the
file name or document properties like author, subject, or even the text. Filter terms can be combined with logical AND and OR. If you do not enter a filter term, the software will automatically split all PDF files entering the watched folder.
Enable and configure the Split File task
In this category, you define the directory in which the separated documents will be saved. Optionally, you can use dynamic
contents for the folder structure and/or the file name. First, determine the base directory, e.g., "D:\Separated files". In
the field Subfolder, you can use dynamic properties (e.g., part of the file name) of the original PDF file. Click on Placeholder and
select the appropriate entry. Various properties of the original document can also be integrated into the file names of the individual
documents. The preview is calculated based on the previously added sample files.
Note: The placeholders here refer to the original file. To name the separated individual documents dynamically (for
example with extracted text components, such as an invoice or protocol number), the separated files must first be saved in an intermediate
directory. This intermediate directory must then be monitored by another profile in which automatic renaming or automatic moving
to the target directory is configured
(see instructions:
Rename PDF files automatically).
Furthermore, you can specify here how the program should behave if a file with the same name already exists.
Determine the type of splitting
Determine here how PDF files are separated. The following options are available:
- Number of pages
- File size
- Top level bookmarks
- Keywords
- Barcode or QR code
- Placeholder (when values of extracted data change)
- Blank pages
To save each page of a document as an individual file, select "Number of pages" and set "Max 1 page". Another
commonly used splitting method is the use of keywords. This can also be used to exclude unwanted pages. For "From -> page
contains:" enter a term that occurs on the first page of each individual document, for example, "protocol number:".
Optionally, for "To -> Page contains:" enter a term that occurs on the last page of each individual document, for
example, "Total:". If one-page documents are expected, the same term can be used again, here "Protocol number:
". Intermediate pages without text or the search term are skipped with this type of splitting, i.e., not extracted.
When splitting documents according to a fixed number of pages, an intermediate directory can again be used and a second profile then
moves only those documents that meet certain filter criteria to the actual target directory.
The software provides additional filtering capabilities allowing you to exclude pages from the splitting process. For example, it is
possible to discard pages without text or pages with or without some specific keywords.
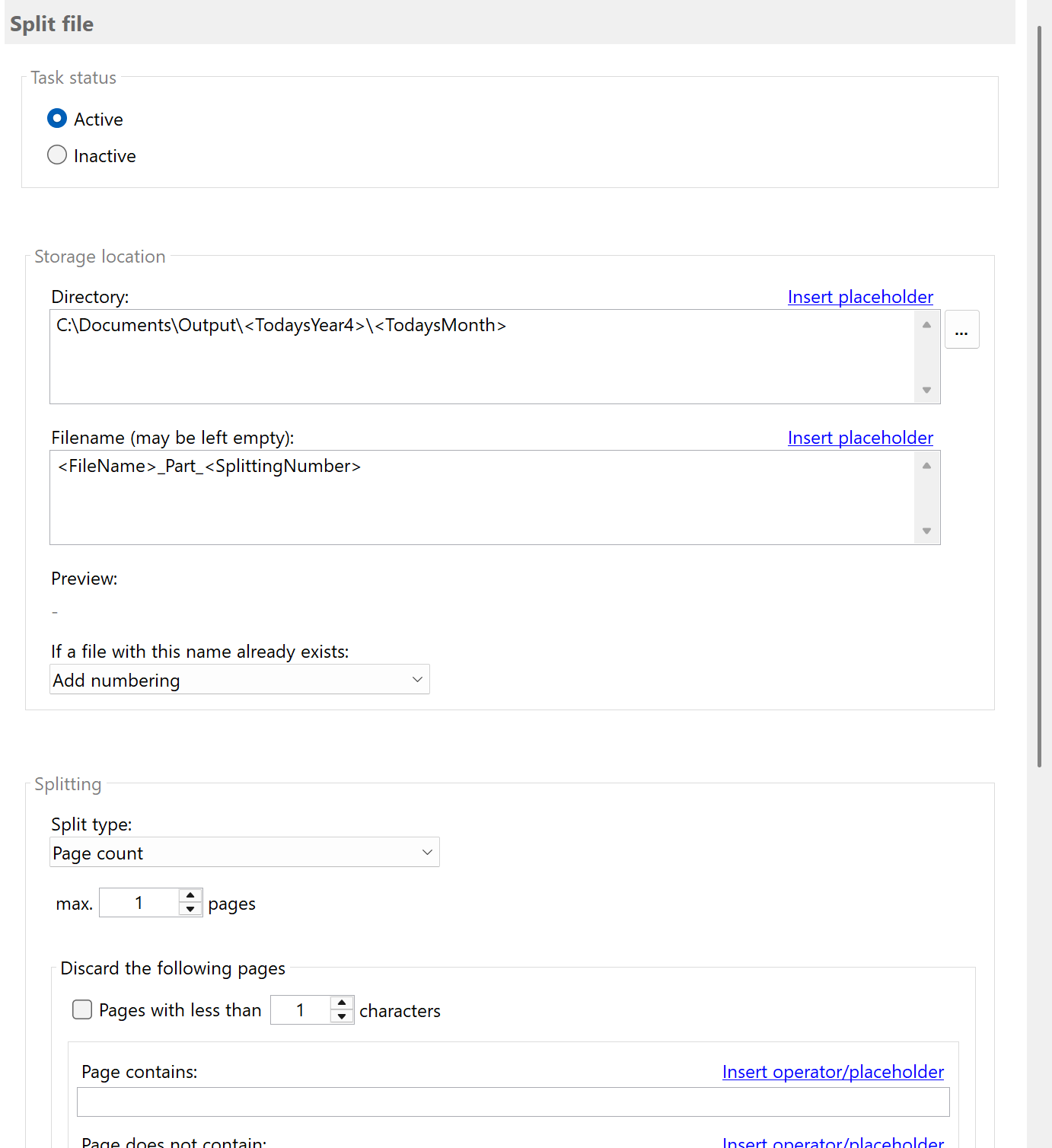
Status notifications
Finally, you can specify whether status messages about the processing of each PDF file (success, error, no
match, no text, ...) should be sent to a specific email address. For sending the status message, either the default Outlook email account
can be used or an email account with user-defined properties. After successfully splitting a PDF document, any
wave file can also be played.
Practical example: Split collective invoices by invoice number
At a glance
- Difficulty: Advanced
- Prerequisites: Understanding data extraction
- Tasks used: Split PDFs, Rename file
- Result: Collective PDF is split into individual invoices, each named with its invoice number
Scenario
You receive a monthly collective PDF with approximately 400 pages containing around 250 invoices. Each invoice
consists of one, two, or three pages. Every page contains the invoice number (e.g., "Inv.No. PH0012345"),
although at varying positions. The goal is to have 250 individual PDF files, each named with its invoice number.
Why are two profiles required? When splitting, only the placeholders
<SplittingNumber> and <SplittingNumberWithLeadingZeros{N}> are available
for file names – but not the extracted value itself (e.g., the invoice number). To name the partial documents
with the invoice number, a second profile is needed that subsequently renames the files.
Workflow overview
Collective PDF (400 pages, 250 invoices)
|
v
Profile 1: Split by placeholder (value change of the invoice number)
|
v
Intermediate folder: CollectiveInvoice_001.pdf, CollectiveInvoice_002.pdf, ... (250 files)
|
v
Profile 2: Rename by extracted invoice number
|
v
Target folder: PH0012345.pdf, PH0012346.pdf, ... (250 files)
Profile 1: Create extraction rule and configure splitting
Create a new profile, e.g., named "Split collective invoices", and set the monitored folder
to where your collective PDFs arrive.
Step A: Create an extraction rule for the invoice number
In the profile settings, navigate to the "Data extraction" category and create a new rule:
- Rule name:
InvoiceNumber
- Determination: Keyword
- Keyword:
Inv.No. (or the keyword used in your documents, e.g., "Invoice No.")
- Data position: Right
- Data type: Text
The keyword "Inv.No." serves as an anchor point. The program searches for this text on each page
and reads the data area to its right – i.e., the actual invoice number (e.g., "PH0012345").
Verify with multiple sample files that the extraction works correctly.
A detailed guide on data extraction can be found here:
Understanding data extraction

Step B: Configure the "Split file" task
Enable the "Split file" task and configure the following settings:
- Splitting method: Placeholder (value change)
- Extraction rule:
InvoiceNumber (the rule you just created)
- Skip pages without valid extraction: Enable if the collective PDF contains a cover page
This splitting method checks the extracted invoice number value on each page. As soon as the value changes
(e.g., from "PH0012345" to "PH0012346"), a new partial document begins. Pages with the
same invoice number are automatically grouped into one document – regardless of whether an invoice
spans one, two, or three pages.
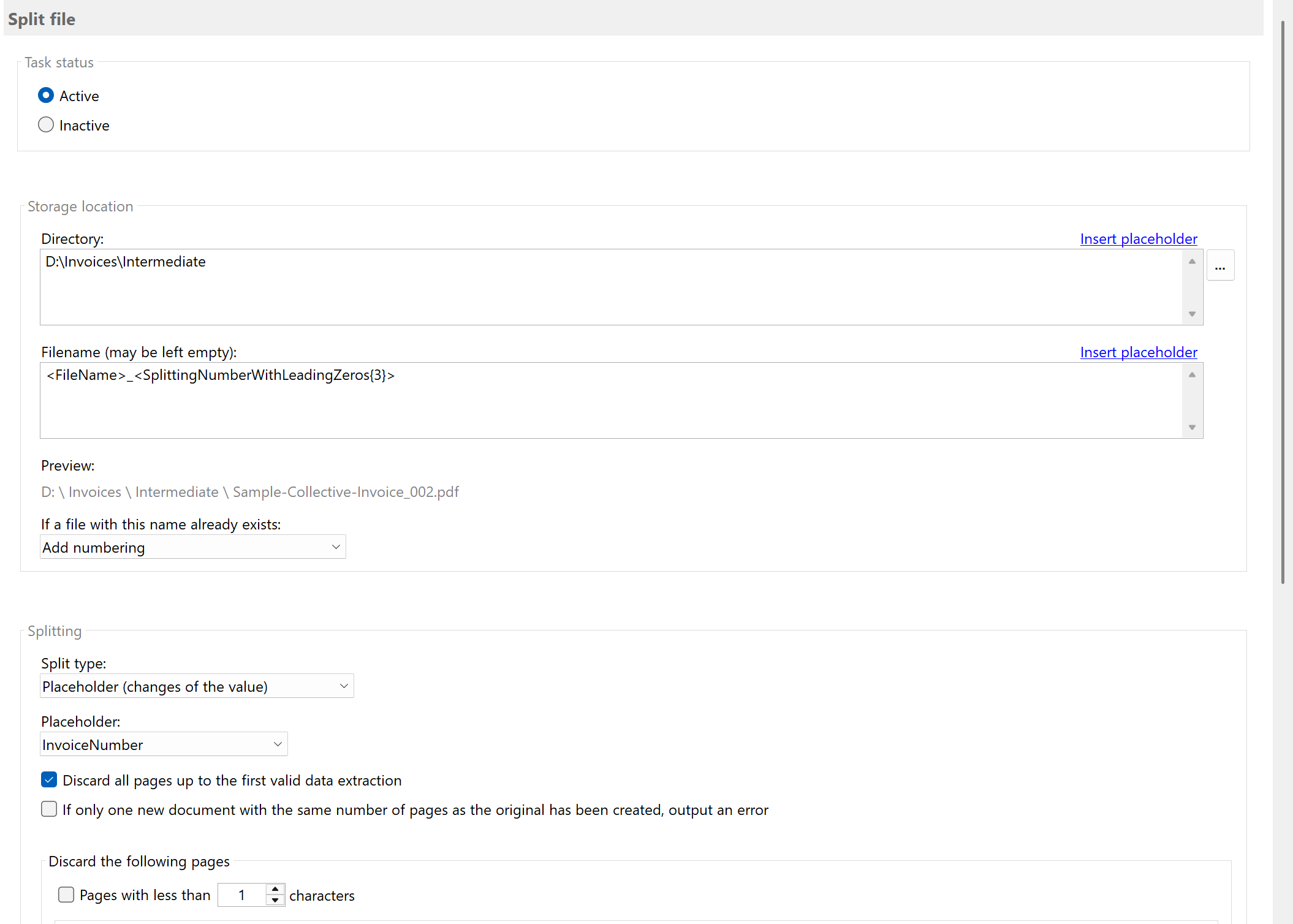
Additionally, configure the storage location for the partial documents:
- Directory:
D:\Invoices\Intermediate (a temporary directory)
- Filename:
<FileName>_<SplittingNumberWithLeadingZeros{3}>
- If a file with the same name exists: Append number
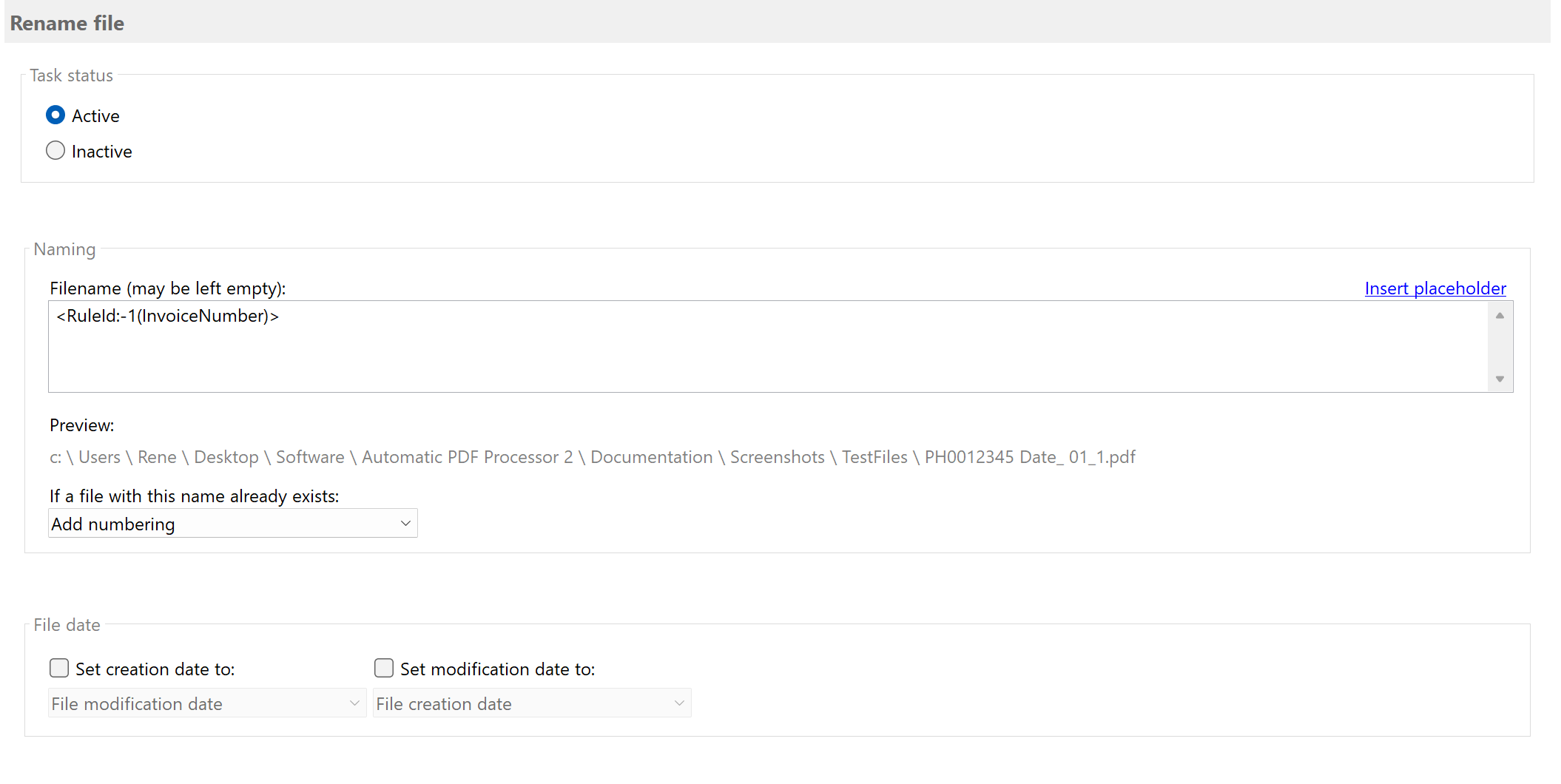
Profile 2: Rename individual invoices by invoice number
Create a second profile, e.g., "Rename invoices", that monitors the intermediate folder
(D:\Invoices\Intermediate).
Step A: Create the same extraction rule
In this profile, create the same extraction rule as in Profile 1:
- Rule name:
InvoiceNumber
- Keyword:
Inv.No.
- Data position: Right
- Data type: Text
Since each file in the intermediate folder now contains only a single invoice, the extraction will return
exactly one invoice number.
Step B: Configure the "Rename file" task
Enable the "Rename file" task and configure the file name using the extraction rule placeholder:
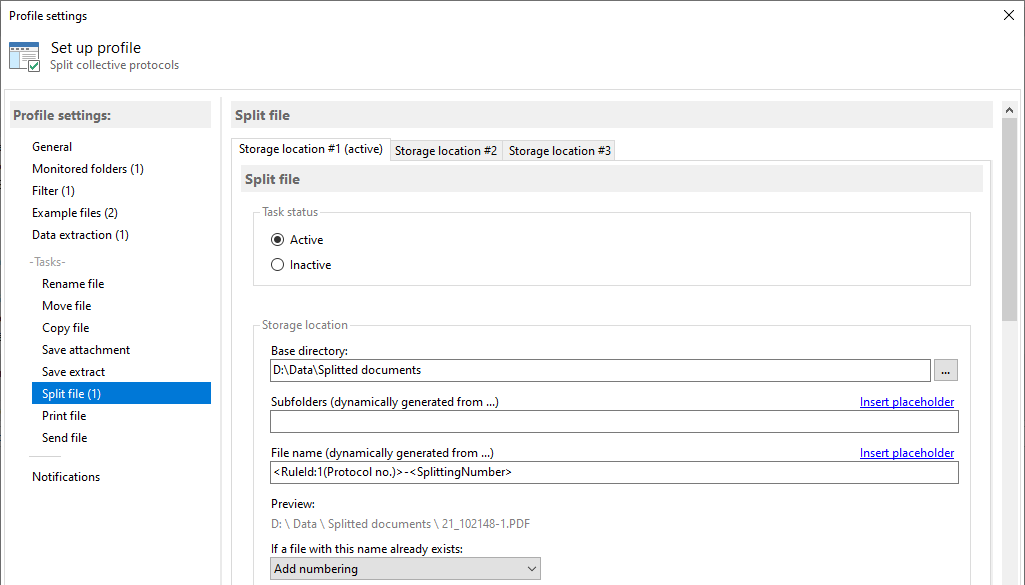
Example configuration
Filename: <RuleId:1(InvoiceNumber)>
Result: PH0012345.pdf
- If a file with the same name exists: Append number
Optionally, you can also enable the "Move file" task to move the renamed files to a final
target directory.
A detailed guide on renaming can be found here:
Rename PDF files automatically
Result
Input: CollectiveInvoice_2024-12.pdf (400 pages, 250 invoices)
Intermediate folder: CollectiveInvoice_2024-12_001.pdf ... _250.pdf
Final result: PH0012345.pdf, PH0012346.pdf, ... (250 files)
Tips:
- Process existing files: Use the "Catch-up processing" function
from the upper toolbar to split collective PDFs already present in the folder.
- Test first: Test the configuration with a small collective PDF
(5–10 invoices) before processing the full document.
- Verify extraction: Add multiple sample files and check the extraction
results in the preview.
- Scanned PDFs: If your collective PDFs are scanned (as images), first enable
the "OCR text recognition" task to make the text searchable.
Other step-by-step instructions
Getting Started
Basic Tasks
PDF Editing
E-Invoicing & Archiving
Practical Examples
Operation & Server
To the product page of Automatic PDF Processor