Instructions for extracting PDF data with Automatic PDF Processor
Video tutorial: Extract invoice data and save it as CSV (with narration and optional subtitles)
Previous steps:
These instructions should be read as part of the step-by-step instructions below. Thus, before extracting the data, the
following steps should have already been taken:
- the profile has been named
- the folder to be monitored has been determined
- filters that may be necessary were set
- sample files were added
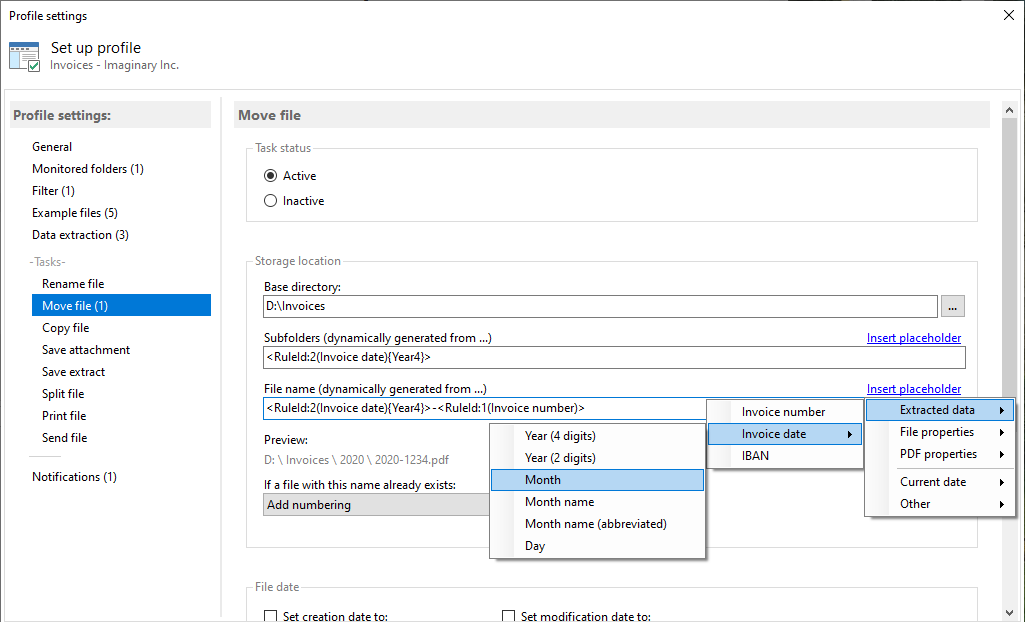
Extract data
Switch to the Data Extraction category and click Create/Edit Rules... to open the rule editor. Once you have some rules created,
you can alternatively double-click on a rule name to navigate directly to it.
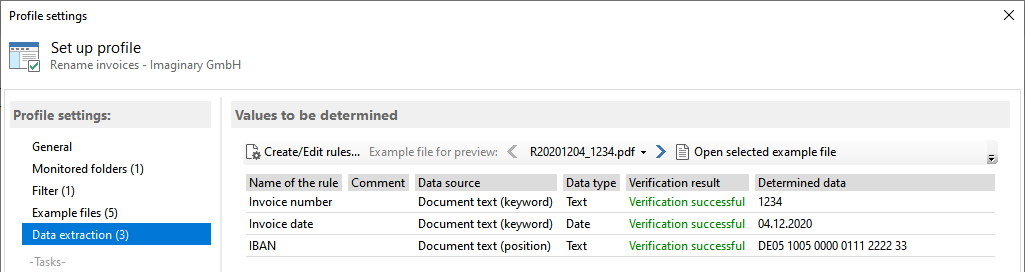
In the Rule Management window, you can set up rules to extract values from the text of the respective PDF file using the
previously defined sample files. For most cases, the data type Text is the right choice. However, when extracting a date,
you should choose the data type of the same name. This way, when you use the extracted value, you have the individual date
components available and can combine them as you wish.
With the data type Query or Query With List, you can store a value in a placeholder depending on the occurrence of certain
keywords. A Query With List enables you to determine categorical values, among other things. For example, for three
different report types (daily report, weekly report, monthly report), the type occurring in the respective document can be
stored in a placeholder named Report Type and used for the name, etc.
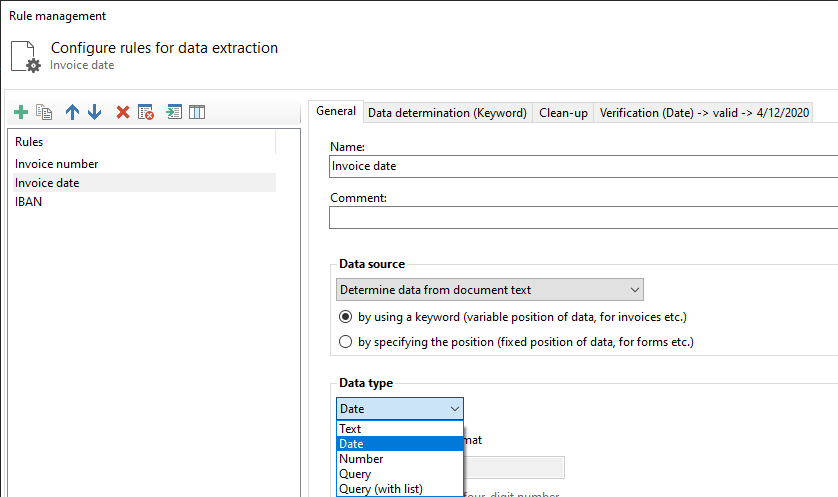
The default setting Text Block covers all subsequent characters of the text block adjacent to the search word and is sufficient
in most cases. However, if the text block overlaps into an unwanted adjacent data range, you must switch to the First Character
setting. With this setting, only the first visible character of the text block is used as the extraction result - so the data
range must be extended here in almost all cases using the tab Extend Data Area next to it.
The preview located below the configuration area shows the currently extracted value.
Subsequent steps:
The extracted PDF data can be used for the file name or path of the respective PDF document to achieve structured storage.
For other use cases, the data can be stored in a separate CSV file or a collective CSV file.