Step-by-step instructions for automatically renaming PDF files with Automatic PDF Processor for Windows
At a Glance
- Difficulty: Intermediate (requires data extraction)
- Time required: ~15 minutes
- Prerequisites: Getting Started tutorial
- Tasks used: Rename file
Video tutorial: Automatically rename PDF files (with narration and optional subtitles)
Introduction
This tutorial shows how to set up a hot folder to auto-rename PDF files with data extracted from their contents. After
creating the profile, you can also rename a batch of pre-existing PDF files using the Catch-up function from the upper toolbar.
Create a new profile
Click the "New profile..." button in the toolbar to create a new profile and open the configuration
window. Enter a suitable name for the profile (e.g., Rename invoices from company Doe) and optionally add a comment, e.g.,
Rename incoming PDF documents by the invoice date. You can have the profile highlighted in color in the log list to quickly
distinguish between the tasks performed.
Determine the folder to be monitored
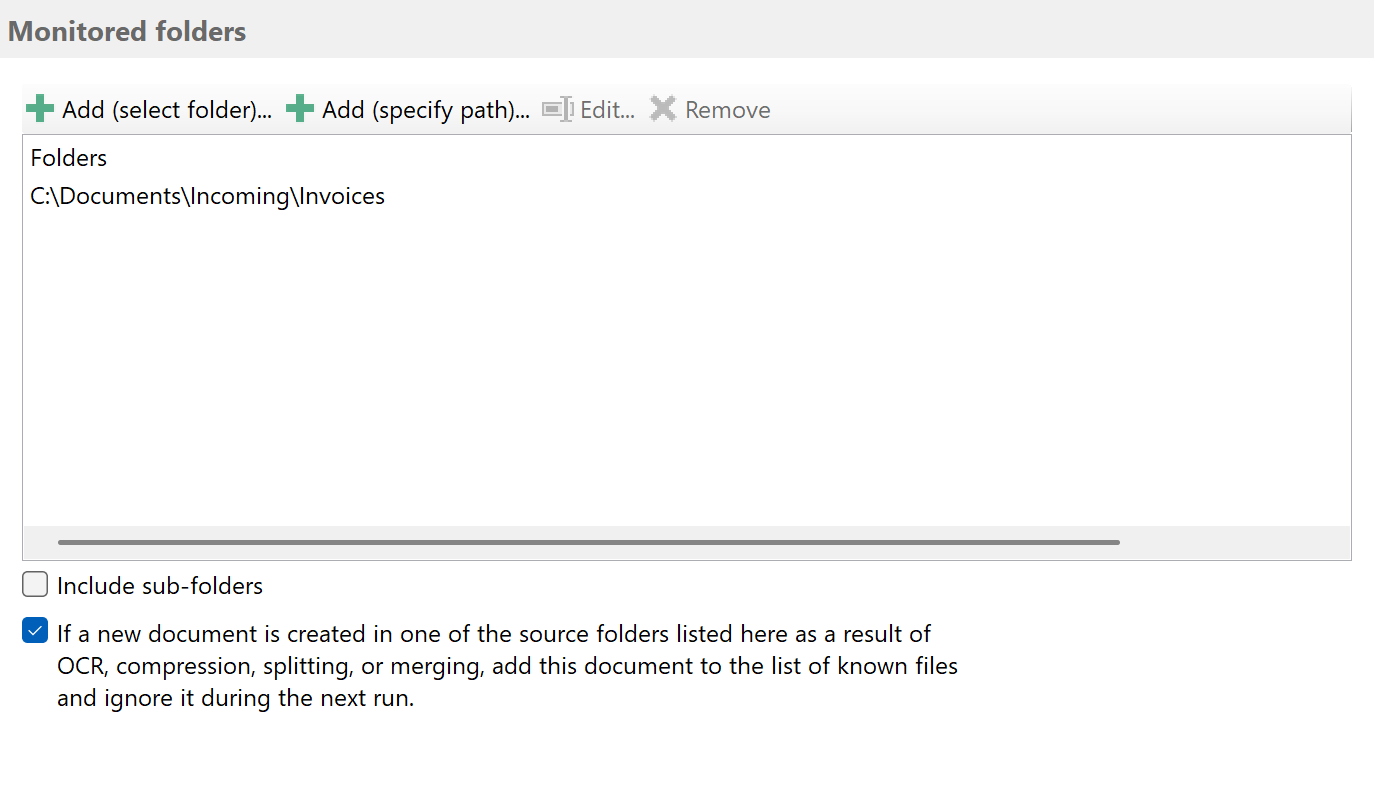
Now specify a folder to be monitored, i.e., one or more folders where the PDF files to be processed are stored. To do this,
click on "Add..." and then select at least one of the listed source folders.
Set filters
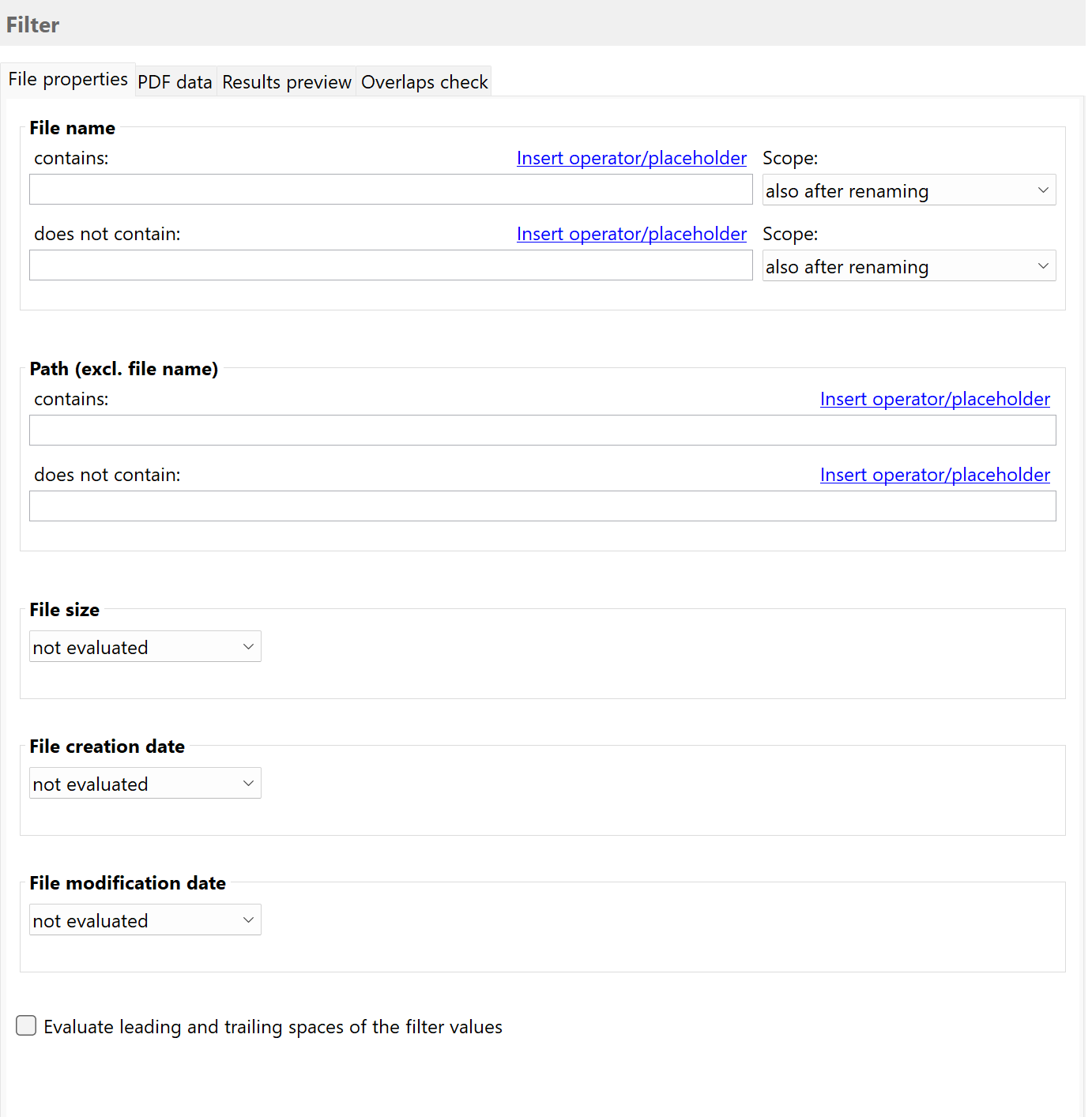
In this category, you can set different filter criteria if needed. For example, enter a term from the PDF content and
a part of the file name. Filter terms can be combined with logical AND and OR. If you do not enter a filter term,
all PDF files entering the watched folder will be renamed. The Results Preview tab shows whether the added sample files
meet the filter criteria.
Add example files
Specify here 5 or more PDF files that correspond to the ones you want to process. You can verify and preview the data
extracted from the file contents based on these sample files. If you only want to print the PDF files, this step is not necessary. However, since the filter-results preview is also based on the sample files, adding them is recommended. It is best to select files here that are located in a separate directory and are not processed, especially
not renamed or moved.
Extract data
Switch to the Data Extraction category and click Create/Edit Rules... to open the rule editor. Once you have some rules created,
you can alternatively double-click on a rule name to navigate directly to it.
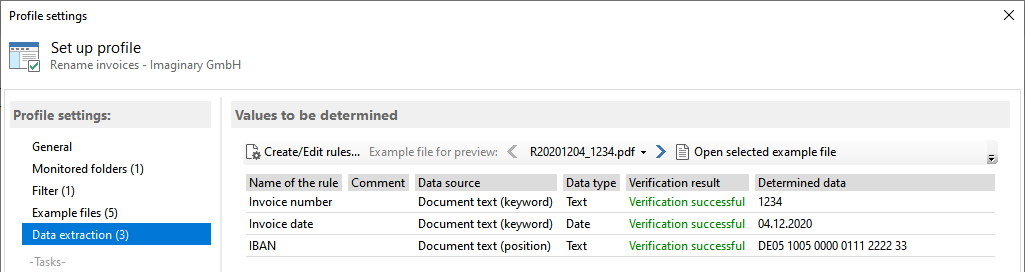
In the Rule Management window, you can set up rules to extract values from the text of the respective PDF file using the
previously defined sample files. For most cases, the data type Text is the right choice. However, when extracting a date,
you should choose the data type of the same name. This way, when you use the extracted value, you have the individual date
components available and can combine them as you wish.
With the data type Query or Query With List, you can store a value in a placeholder depending on the occurrence of certain
keywords. A Query With List enables you to determine categorical values, among other things. For example, for three
different report types (daily report, weekly report, monthly report), the type occurring in the respective document can be
stored in a placeholder named Report Type and used for the name, etc.
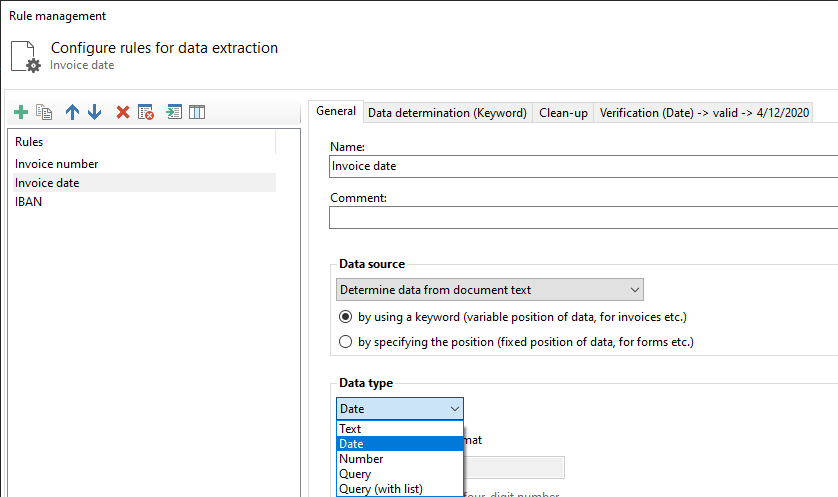
The default setting Text Block covers all subsequent characters of the text block adjacent to the search word and is sufficient
in most cases. However, if the text block overlaps into an unwanted adjacent data range, you must switch to the First Character
setting. With this setting, only the first visible character of the text block is used as the extraction result - so the data
range must be extended here in almost all cases using the tab Extend Data Area next to it.
The preview located below the configuration area shows the currently extracted value.
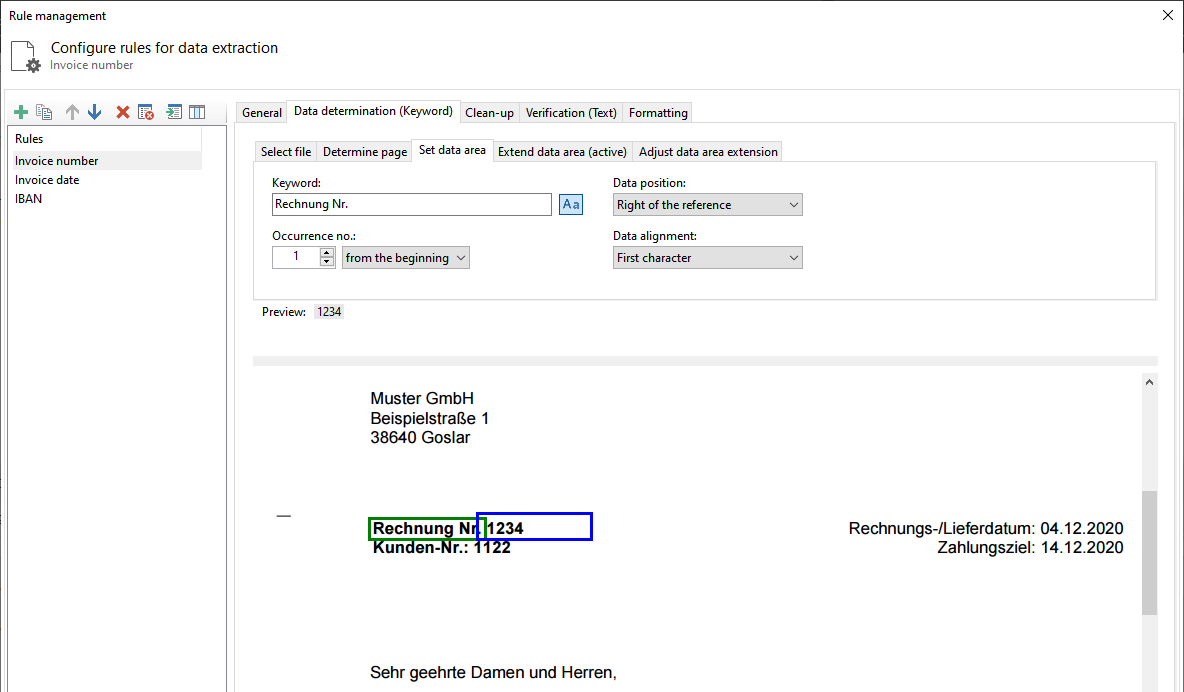
Activate and configure task Rename file
Next, select the category Rename File and set the task status to Active.
Placeholders allow you to rename PDF documents based on content. Any number of placeholders can be used for the file name -
combined however you like. A placeholder can either stand for properties of the PDF file
or values extracted from the document text, such as invoice date, invoice number, etc. To use placeholders, click
the link of the same name above the input field with the label File Name and select the corresponding menu item.
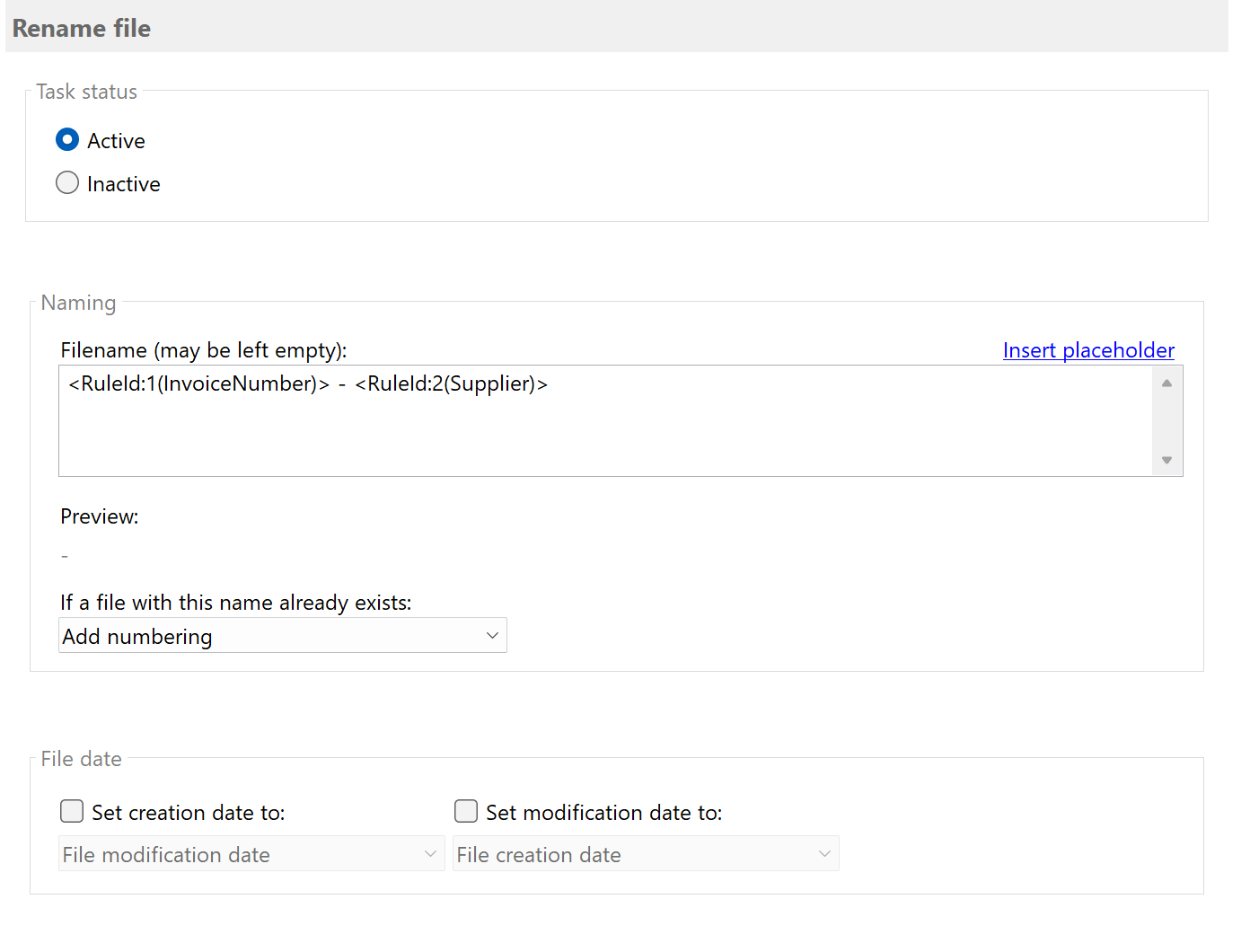
Example: Rename with extracted data
Click "Insert placeholder" and select your extraction rules. A typical configuration:
<RuleId:1(InvoiceNumber)>_<RuleId:2(InvoiceDate)>
Result: INV-12345_2024-12-15.pdf
Here you can also determine the behavior of the program in case a file with the same name already exists. For example,
select Add Numbering or Cancel Operation.
Optionally, you can also adjust the creation or modification date of the processed file. For example, you can set the file
date to the current date or to a date extracted from the file contents.
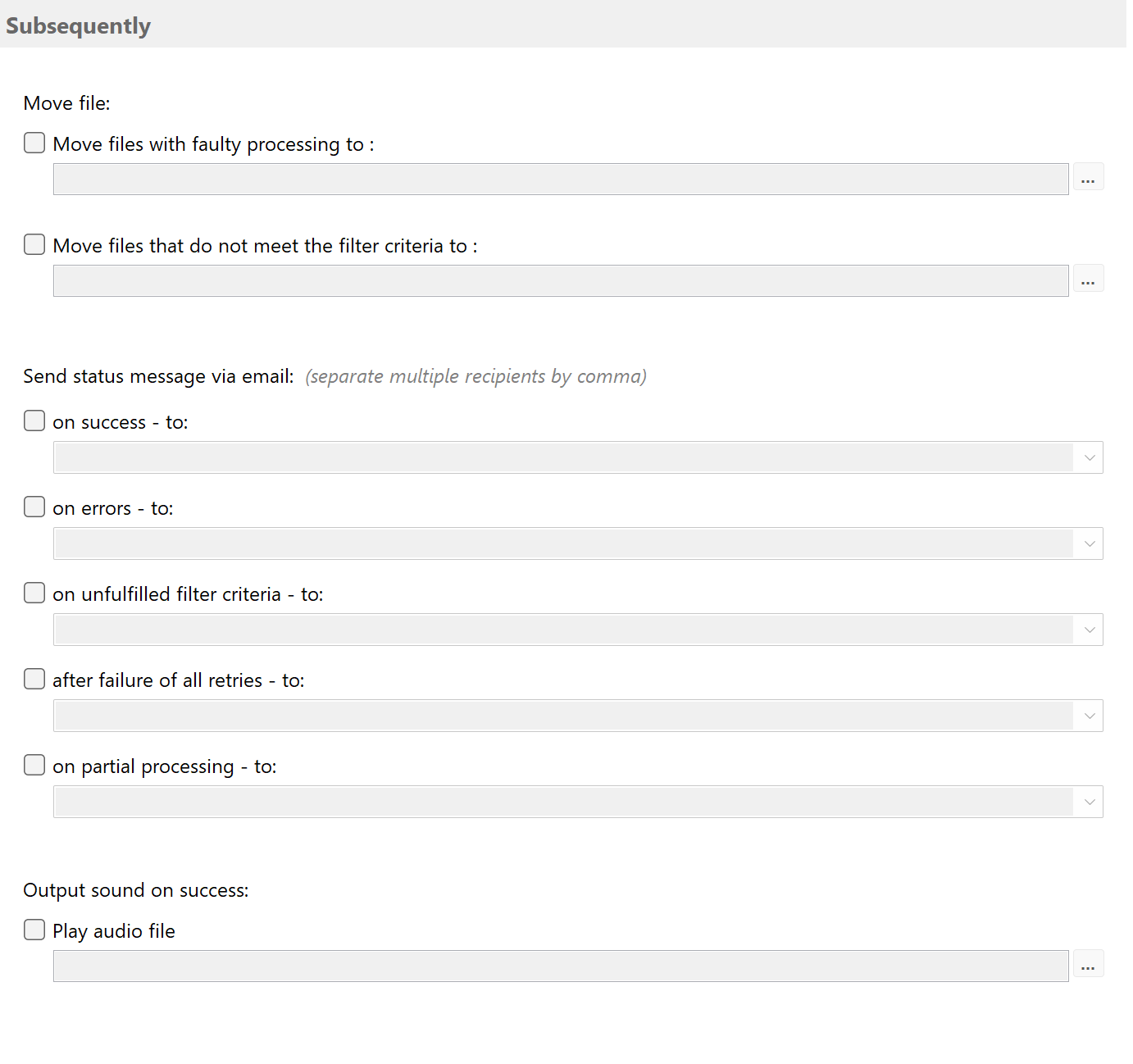
Status notifications
Finally, you can specify in this category whether status messages (success, error, no match, no text, ...) about
processing each PDF document should be sent to a specific email address. You can either use the Outlook email
account set as the default, Exchange Online, or an SMTP server to send the status messages.
Result
After completing this configuration, your profile will automatically:
- Monitor the specified folder(s) for new PDF files
- Check each file against your filter criteria (if configured)
- Extract data from matching PDFs using your extraction rules
- Rename files according to your filename pattern with placeholders
- Log all operations in the main window for review
Tip: Use the Catch-up function in the toolbar to process existing PDF files
that were already in the folder before the profile was created.